NOSQL和SQL区别
- SQL数据库,指关系型数据库 ,主要代表:SQL Server,Oracle,MySQL,PostgreSQL。关系型数据库存储结构化数据。这些数据逻辑上以行列二维表的形式存在,每一列代表数据的一种属性,每一行代表一个数据实体。
- NoSQL指非关系型数据库 ,主要代表:MongoDB,Redis。NoSQL 数据库逻辑上提供了不同于二维表的存储方式,存储方式可以是JSON文档、哈希表或者其他方式。
选择 SQL vs NoSQL,考虑以下因素。
ACID vs BASE:关系型数据库支持 ACID 即原子性,一致性,隔离性和持续性。相对而言,NoSQL 采用更宽松的模型BASE , 即基本可用,软状态和最终一致性。从实用的角度出发,我们需要考虑对于面对的应用场景,ACID 是否是必须的。比如银行应用就必须保证ACID,否则一笔钱可能被使用两次;又比如社交软件不必保证 ACID,因为一条状态的更新对于所有用户读取先后时间有数秒不同并不影响使用。
扩展性对比:NoSQL数据之间无关系,这样就非常容易扩展,也无形之间,在架构的层面上带来了可扩展的能力。比如 redis 自带主从复制模式、哨兵模式、切片集群模式。相反关系型数据库的数据之间存在关联性,水平扩展较难 ,需要解决跨服务器 JOIN,分布式事务等问题。
数据库三大范式是什么?
- 第一范式(1NF):要求数据库表的每一列都是不可分割的原子数据项。
- 第二范式(2NF):在1NF的基础上,非码属性必须完全依赖于候选码(在1NF基础上消除非主属性对主码的部分函数依赖)第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)
- 第三范式(3NF):在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关
MySQL 怎么连表查询?
- 内连接 (INNER JOIN)
- 左外连接 (LEFT JOIN)
- 右外连接 (RIGHT JOIN)
- 全外连接 (FULL JOIN)
MySQL如何避免重复插入数据?
- 使用UNIQUE约束:在表的相关列上添加UNIQUE约束,确保每个值在该列中唯一。
- 使用INSERT … ON DUPLICATE KEY UPDATE:这种语句允许在插入记录时处理重复键的情况。如果插入的记录与现有记录冲突,可以选择更新现有记录:
- 使用INSERT IGNORE: 该语句会在插入记录时忽略那些因重复键而导致的插入错误。
选择哪种方法取决于具体的需求:
- 如果需要保证全局唯一性,使用UNIQUE约束是最佳做法
- 如果需要插入和更新结合可以使用 ON DUPLICATE KEY UPDATE
- 对于快速忽略重复插入, INSERT IGNORE 是合适的选择
CHAR 和 VARCHAR有什么区别?
- CHAR是固定长度的字符串类型,定义时需要指定固定长度,存储时会在末尾补足空格。CHAR适合存储长度固定的数据,如固定长度的代码、状态等,存储空间固定,对于短字符串效率较高。
- VARCHAR是可变长度的字符串类型,定义时需要指定最大长度,实际存储时根据实际长度占用存储空间。VARCHAR适合存储长度可变的数据,如用户输入的文本、备注等,节约存储空间。
varchar后面代表字节还是字符?
VARCHAR 后面括号里的数字代表的是字符数,而不是字节数。
字符的字节长度取决于所使用的字符集。
- ASCII 字符集:每个字符占用 1 个字节
- UTF - 8 字符集,它的每个字符可能占用 1 到 4 个字节
int(1)和int(10) 在mysql有什么不同?
- 本质是显示宽度,不改变存储方式: INT 的存储固定为 4 字节,所有 INT 占用的存储空间 均为 4 字节。括号内的数值是显示宽度,用于在 特定场景下 控制数值的展示格式。
- 唯一作用场景: ZEROFILL 补零显示(不加ZEROFILL无效果),当字段设置 ZEROFILL 时:数字显示时会用前导零填充至指定宽度。比如,字段类型为 INT(4) ZEROFILL ,实际存入 5 → 显示为 0005 ,实际存入 12345→ 显示仍为 12345 (宽度超限时不截断)
Text数据类型可以无限大吗?
MySQL 4 种text类型的最大长度如下:
- TINYTEXT: 28 255 bytes
- TEXT:216约64kb
- MEDIUMTEXT:224bytes 约16Mb
- LONGTEXT:232bytes 约4Gb
IP地址如何在数据库里存储?
IPv4 地址是一个 32 位的二进制数,通常以点分十进制表示法呈现
字符串类型的存储方式:直接将 IP 地址作为字符串存储在数据库中,比如可以用 VARCHAR(15) 来存储。
- 优点:直观易懂,方便直接进行数据的插入、查询和显示,不需要进行额外的转换操作。
- 缺点:占用存储空间较大,字符串比较操作的性能相对较低,不利于进行范围查询。
整数类型的存储方式:将 IPv4 地址转换为 32 位无符号整数进行存储,常用的数据类型有 INTUNSIGNED 。
- 优点:占用存储空间小,整数比较操作的性能较高,便于进行范围查询。
- 缺点:需要进行额外的转换操作,不够直观,增加了开发的复杂度。
说一下外键约束
外键约束是 关系型数据库 中用于维护 表与表之间关联关系 的核心机制,它能强制保证数据的引用完整性,避免出现无效的关联数据。
优点:
- 保证数据完整性:强制关联合法,避免孤儿数据,让数据更可靠。
- 简化业务逻辑:通过级联操作,减少手动同步关联数据的代码(如删除用户时无需手动删除订单)。
- 明确表关系:外键是表之间关联关系的 “显式声明”,便于开发者理解数据库结构。
缺点:
- 性能开销:外键约束会增加数据库的写入开销,大数据量、高并发场景下可能影响性能。
- 灵活性降低:外键强制绑定表关系,若业务需求变更,修改外键结构会比较麻烦。
- 分布式场景不适用:跨数据库、跨服务器的表无法建立外键。
MySQL的关键字in和exist
IN 用于检查左边的表达式是否存在于右边的列表或子查询的结果集中。如果存在,则 IN 返回 TRUE ,否则返回 FALSE 。
EXISTS 用于判断子查询是否至少能返回一行数据。它不关心子查询返回什么数据,只关心是否有结果。如果子查询有结果,则 EXISTS 返回 TRUE ,否则返回 FALSE 。
区别与选择:
- 性能差异:在很多情况下, EXISTS 的性能优于 IN ,特别是当子查询的表很大时。这是因为EXISTS 一旦找到匹配项就会立即停止查询,而 IN 可能会扫描整个子查询结果集。
- 使用场景:如果子查询结果集较小且不频繁变动, IN 可能更直观易懂。而当子查询涉及外部查询的每一行判断,并且子查询的效率较高时,EXISTS 更为合适。
- NULL值处理: IN 能够正确处理子查询中包含NULL值的情况,而 EXISTS 不受子查询结果中NULL值的影响,因为它关注的是行的存在性,而不是具体值。
mysql中的一些基本函数,你知道哪些?
- 字符串函数
- CONCAT(str1, str2, …):连接多个字符串,返回一个合并后的字符串。
- LENGTH(str):返回字符串的长度
- SUBSTRING(str, pos, len):从指定位置开始,截取指定长度的子字符串
- REPLACE(str, from_str, to_str):将字符串中的某部分替换为另一个字符串。
- 数值函数
- ABS(num):返回数字的绝对值。
- POWER(num, exponent):返回指定数字的指定幂次方。
- 日期和时间函数
- NOW():返回当前日期和时间。
- CURDATE():返回当前日期。
- 聚合函数
- COUNT(column):计算指定列中的非NULL值的个数。
- SUM(column):计算指定列的总和。
- AVG(column):计算指定列的平均值。
- MAX(column):返回指定列的最大值。
- MIN(column):返回指定列的最小值。
SQL查询语句的执行顺序是怎么样的?
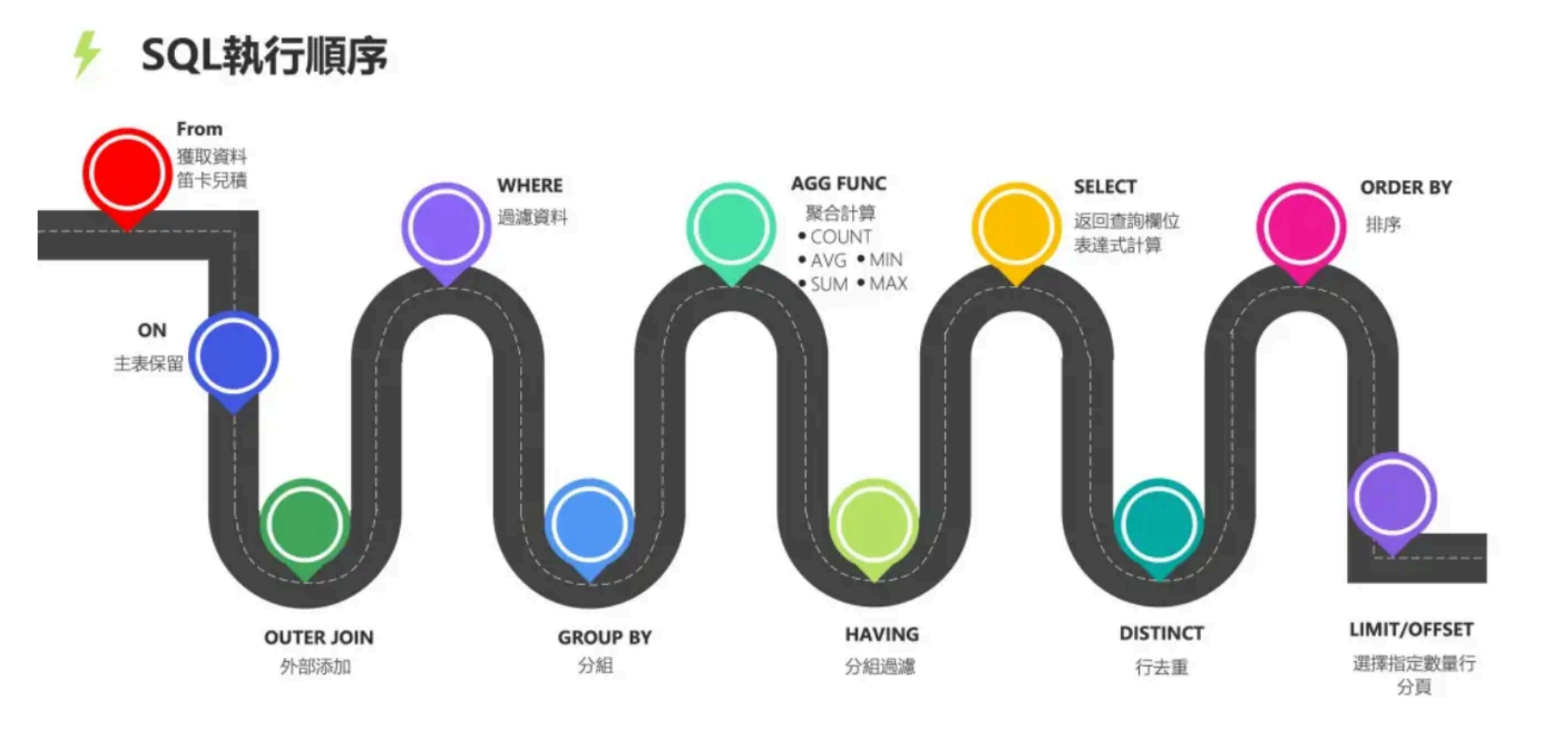
所有的查询语句都是从FROM开始执行,在执行过程中,每个步骤都会生成一个虚拟表,这个虚拟表将作为下一个执行步骤的输入,最后一个步骤产生的虚拟表即为输出结果。
如何用 MySQL 实现一个可重入的锁?
创建一个保存锁记录的表:
1 | CREATE TABLE `lock_table` ( |
加锁的实现逻辑:
- 开启事务
- 执行
SQL SELECT holder_thread, reentry_count FROM lock_table WHERE lock_name =? FOR UPDATE,查询是否存在该记录:- 如果记录不存在,则直接加锁,执行
INSERT INTO lock_table (lock_name, holder_thread, reentry_count) VALUES (?,?, 1) - 如果记录存在,且持有者是同一个线程,则可重入,增加重入次数,执行
UPDATE lock_table SET reentry_count = reentry_count + 1 WHERE lock_name =?
- 如果记录不存在,则直接加锁,执行
- 提交事务
解锁的逻辑:
- 开启事务
- 执行 SQL
SELECT holder_thread, reentry_count FROM lock_table WHERE lock_name =?,查询是否存在该记录:- 如果记录存在,且持有者是同一个线程,且可重入数大于 1 ,则减少重入次数
UPDATE lock_table SET reentry_count = reentry_count - 1 WHERE lock_name =? - 如果记录存在,且持有者是同一个线程,且可重入数小于等于 1 ,则完全释放锁,
DELETE FROM lock_table WHERE lock_name =?
- 如果记录存在,且持有者是同一个线程,且可重入数大于 1 ,则减少重入次数
- 提交事务